
프로젝트
- Google Inception V3를 이용한 유방암 진단 프로그램
- 개인 프로젝트
- 개발 도구 : Inception V3, Python
프로젝트 기간
2019.5 - 2019.6
분야 및 동기
현대 인간 삶의 수준이 향상됨에 따라 건강한 삶의 욕구 및 관심도가 증가하고 있다. 하지만 건강에 대한 욕구와 다르게 환경적·유전적 요인 등 다양한 요인에 의해 암 발병률이 높아지고 있는 추세다. 그중 유방암은 전 세계적으로 여성암 1위 를 차지할 정도로 발병률이 높다.
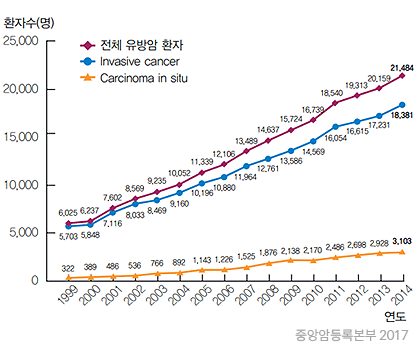
유방암은 미국 및 서구의 여러 나라에서 여성에게 발생하는 가장 흔한 암으로 국내에서도 생활 패턴의 서구화 경향, 조기 유방암 검진에 대한 인식의 변화 등으로 그 빈도는 매년 증가하고 있다.
2003년 한국유방암학회의 보고에 따르면 2002년 한해 동안 7551예의 환자가 새로이 발생하여 국내의 병원에서 치료를 받았으며, 이러한 환자의 빈도는 매년 증가추세를 보이고 있다. 그러나 유방암 의심 환자들 중 실제 암으로 판정 받는 비율이 0.6%에 그친다.
이렇듯 검사 비용대비 판정률이 낮게 나오면서 실제 조기진단의 어려움이 있다.
유방암 자료는 미국 TCIA(The Cancer Image Archive)에서 서비스 중인 임상정보를 삭제한 유방암 MRI(magnetic resonance imaging) 및 일반 검사 이미지인 MG(MammoGraphy)를 사용하였다.
데이터 수집
미국 TCIA 데이터베이스로부터 TCGA(The Cancer Genome Atlas) 유방암 이미지 데이터(BRCA)를 확보했다. 데이터는 139명 환자의 23만 167개 이미지(용량 88.58GB)로 MRI,
MG(일반 유방암 검사) 검사 이미지다. 환자 별로 수십에서 수백 장까지의 이미지를 갖도록 구성되어 있다.
유방암 MRI 이미지는 다양한 방향에서 촬영하는데 이번 분석에서는 분석 복잡도(complexity)를 줄이기 위해 왼쪽 가슴 측면 이미지만 사용했다. 환자의 모든 이미지를 사용하지 않고 종양 조직(tumor)이 직관적으로 확인되는 이미지만 선별했다. 최종 89명 환자에 대한 1568개이미지를 분석에 이용하기 위해 추출했다.
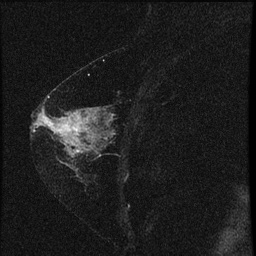
[그림 2] 분석에 사용된 이미지 샘플
[그림 2]는 분석에 사용된 이미지 샘플이다. 가운데 하얀 것이 종양이다. 종양이 없는 이미지 데이터를 찾기 어려워 왼쪽 가슴 이미지 데이터만 사용했다. 한쪽에만 종양이 있을 경우 다른 쪽에서 종양이 없는 이미지를 얻을 수 있을 것이라고 생각했다.
1568개의 데이터 중 종양이 있다고 판단되는 이미지 데이터 925개와 종양이 없다고 판단되는 643개 이미지로 나누었다. 종양을 정확하게 판별 할 수 있는 전문 지식이 없으므로 육안으로 구분 가능한 데이터 위주로 사용하였다.TCIA에서 제공하는 이미지 데이터는 DICOM(Digital Imaging and COmmunications in Medicine) 포맷 파일로 JPEG 이미지로 변환·저장했다.
모은 데이터는 [표 1]과 같다
| 구분 | 암 | 정상 |
|---|---|---|
| 샘플 수(명) | 89 | 89 |
| 이미지 수(개) | 925 | 643 |
| 이미지 포맷 | JPEG | JPEG |
| 이미지 크기(픽셀) | 256*256 | 256*256 |
| 파일 크기(KB) | 25.2 | 25.2 |
[표 1] 수집한 데이터
특징 세그멘테이션
그렇다면 실제 픽셀 값의 조작으로 암/정상을 구분할 수 있는 특징(종양)을 찾을 수 있을지 생각했다. 일단 하나의 이미지 샘플만 암/정상을 판별할 수 있는지 테스트 했다.
위 데이터 탐색에서도 설명했듯이 종양의 픽셀 값은 다른 조직보다 밝고 여러 개 픽셀이 모여 밀도가 높기 때문에 픽셀의 밝기 강도만을 이용해 종양 조직을 분할(segmentation)해 보았다.

[그림 3]는 Image Thresholding을 통해 이미지 임계 처리를 한 것이다. 여기에서 두번째 그림이 제일 종양의 모양과 크기를 구분하기 쉽다는 것을 볼 수 있다.
유방암 이미지 판별과 평가
모형을 구축하기 위해 사전에 수집된 1,494 이미지 데이터는 모형을 훈련 시키기 위한 데이터 1,294개, 모형을 검증할 데이터 200개로 이미지를 구분했다.
판별모형 구현은 현재 딥러닝 및 AI분야에서 많이 사용되고 있는 파이썬 기반의 텐서플로우(TensorFlow)를 이용했다. 딥러닝 방법은 2012년 구글에서 자체 이미지 분류를 위해 구축해 놓은 모형인 Inception V3를 유방암 이미지를 이용해 다시 훈련시켜 사용했다.
Inception V3을 실행하기 위해서는 TensorFlow-gpu가 필요하다. TensorFlow-gpu 설치 과정에서 CUDA 와 cuDNN을 다운받아 설치했다.


이미지 학습을 실행한 후 breastCancer 경우와 breastnonCancer경우의 이미지를 각각 테스트
해보았다. 종양이 있는 경우에는 정확도가 77%로 나왔다. 종양이 없는 경우는 98%의 정확도를
보였다.
분석 결과의 시사점 및 결론
이미지 데이터 딥러닝 분석 방법 중 가장 정확도가 높다는 Inception V3이라도 정확도가 높지 않았다. 물론 전문적인 의학 지식이 없이 사진을 분류 했기 때문에 이 과정에서도 정확도가 감소했다고 생각한다. 분석의 정확도가 보다 중요한 의료 분야에서는 실제적으로 활용되기에는 낮은 수치라고 판단된다. 정확도를 높이기 위해서는 특정 이미지 판별 모형을 특정 이미지 형태만 이용하는 것이나 아니라 일반적인 유방암 이미지 전체를 이용해 재훈련시키고 모델을 최적화해 정확도를 높이는 과정이 필요한다. 만약 이러한 기술이 실제에서 활용된다면 보다 저렴하고 간단한 방법으로 유방암 검사를 할 수 있을 것이다. 또한 다른 장기도 판별할 수 있도록 하고싶다. 또한 각 장기의 조직에 대한 처리를 정확하게 한다면 여러 방면으로 활용 가능할 것이다.
기술은 인간을 위해서 개발되어야 한다고 생각한다. 인간의 존엄성과 편리성을 위한 기술 발달을
위하여 많은 노력을 해야한다.